Försäkringskostnader
Syfte med analysen
Syftet med denna analys var att undersöka vilka faktorer som verkar hänga ihop med försäkringskostnader och att testa om en regressionsmodell kan användas för att förklara skillnader i kostnad mellan olika kunder.
Data och förberedelser
Datasetet innehåller både numeriska och kategoriska variabler, till exempel ålder, BMI, rökning, motionsnivå, kronisk sjukdom och försäkringsplan.
I analysen började jag med att läsa in datat och kontrollera struktur, variabeltyper och saknade värden. Därefter genomfördes datastädning. Saknade värden i bmi och annual_checkups ersattes med medianen. Saknade värden i exercise_level ersattes med "unknown".
Vid kontroll av de kategoriska variablerna upptäcktes mindre inkonsekvenser i skrivsätt, till exempel stora och små bokstäver i vissa kategorier. Därför standardiserades dessa variabler innan de gjordes om till faktorer.
Jag skapade också en ny variabel, history_score, genom att summera prior_accidents och prior_claims. Tanken var att få ett enkelt mått på tidigare historik.
Några tydliga mönster i datat
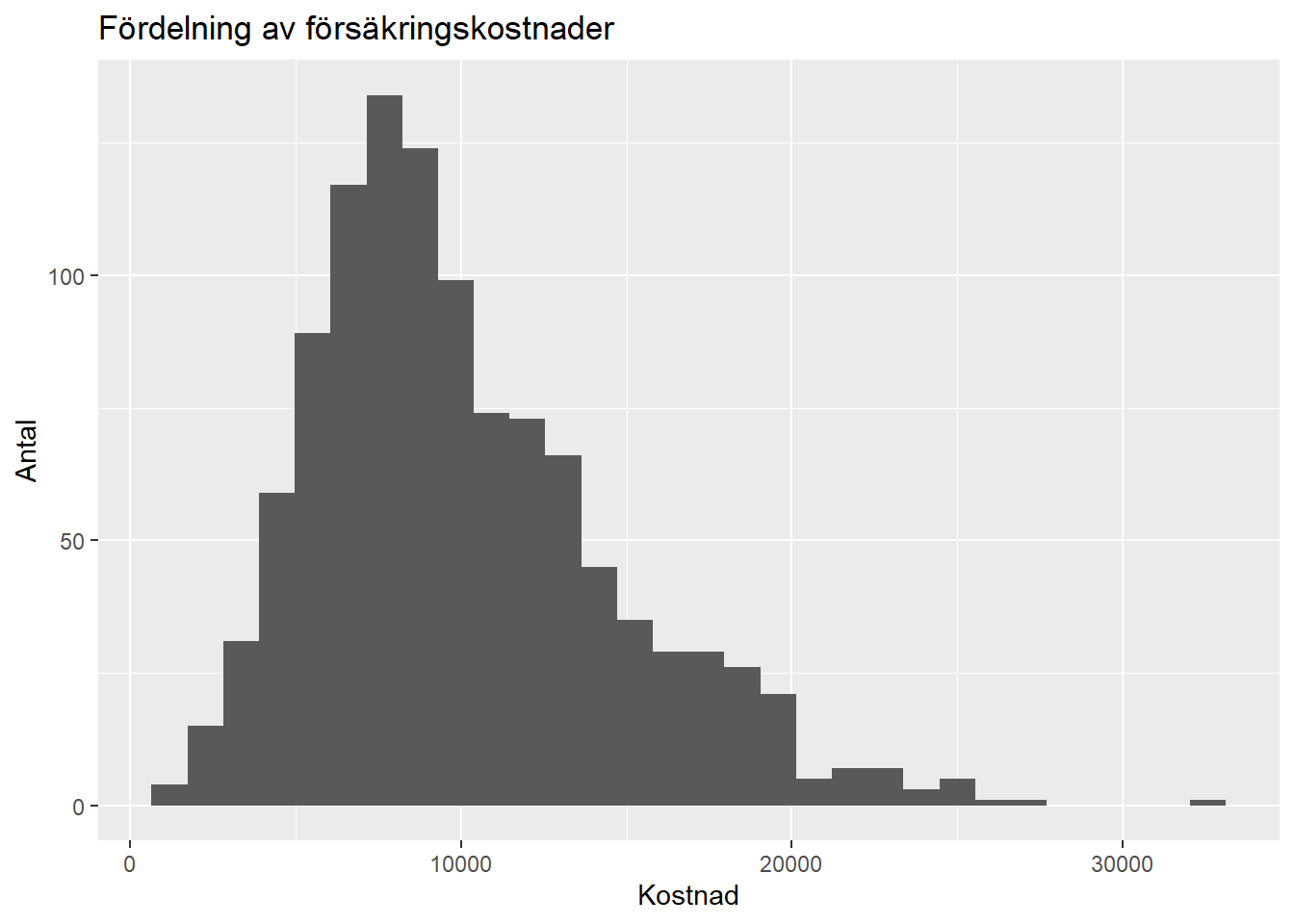
Hur kostnaderna är fördelade
# A tibble: 1 × 5
mean_charges median_charges sd_charges min_charges max_charges
<dbl> <dbl> <dbl> <dbl> <dbl>
1 10060. 9124. 4574. 1204. 32559.Fördelningen av försäkringskostnader är inte helt symmetrisk. De flesta observationer ligger i den lägre eller mellersta delen av fördelningen, men det finns också ett mindre antal kunder med betydligt högre kostnader. Det tyder på att vissa grupper i datat har klart högre kostnader än andra.
BMI, rökning och kostnad
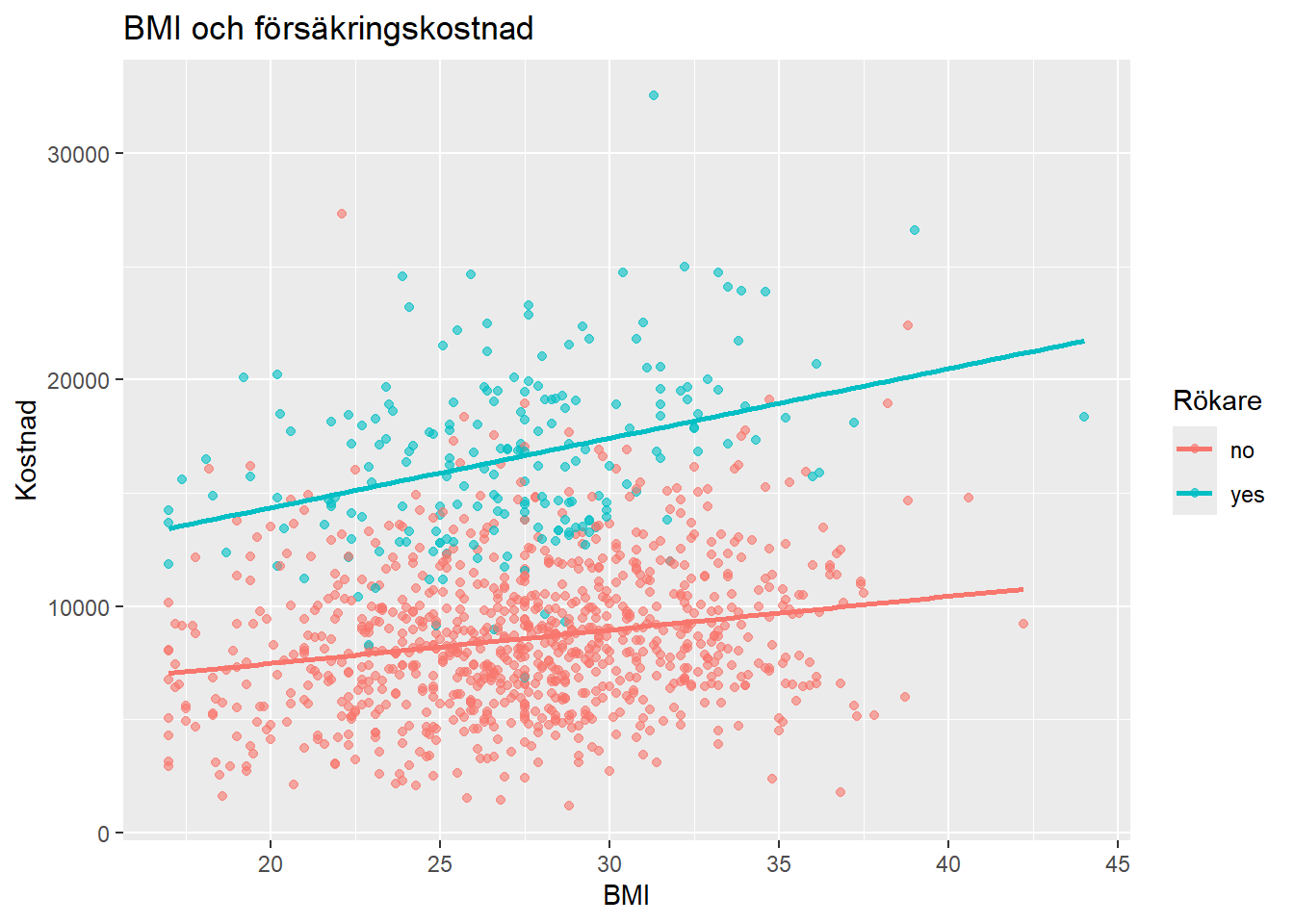
Figuren visar ett positivt samband mellan BMI och kostnad. Sambandet ser särskilt tydligt ut bland rökare, som generellt har högre kostnader än icke-rökare vid liknande BMI-nivåer. Detta tyder på att rökning är en viktig faktor i datasetet.
Skillnader mellan försäkringsplaner
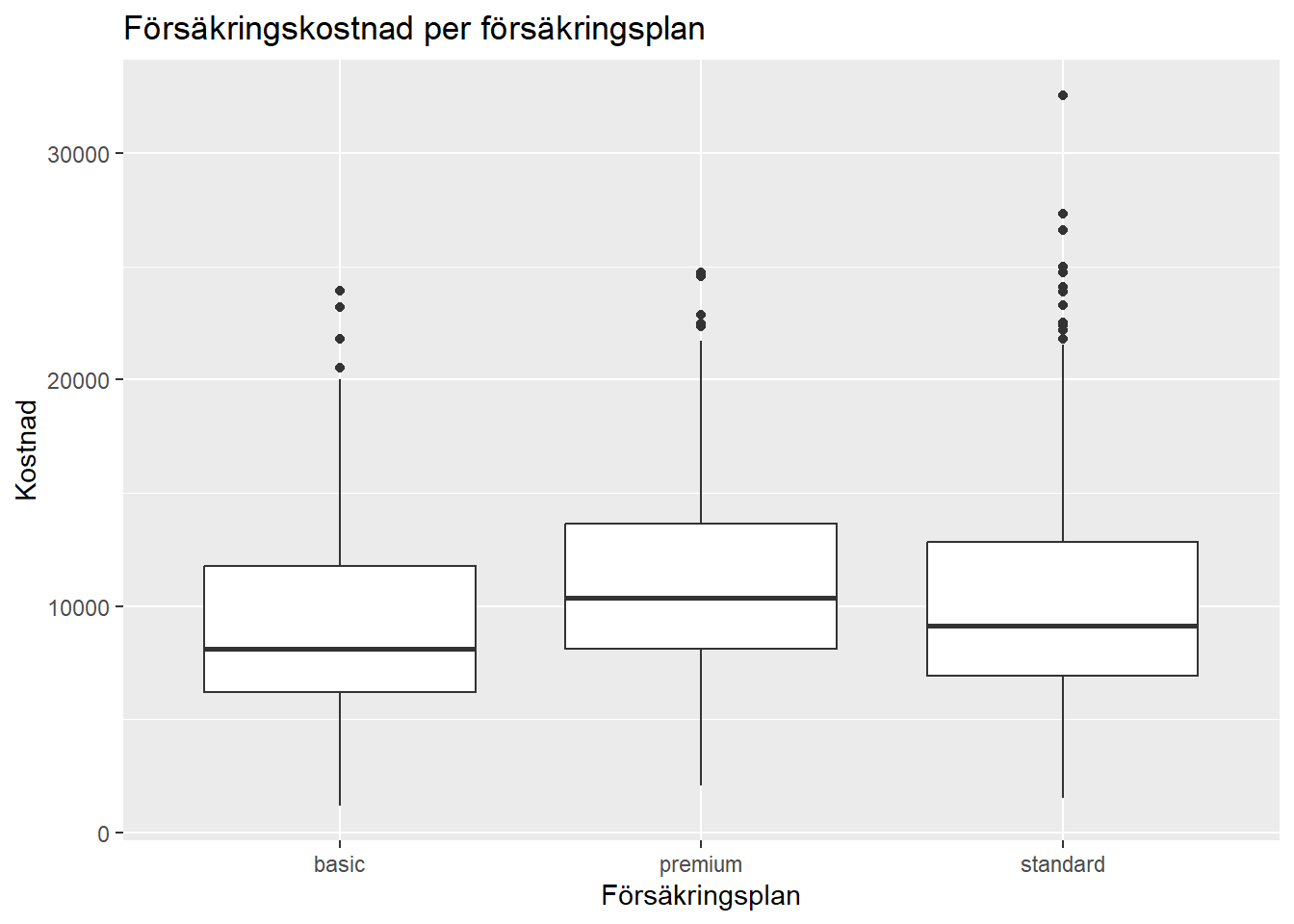
Boxplotten visar skillnader mellan olika försäkringsplaner. Premium verkar ha högre median än basic, medan standard också ligger högre än basic. Samtidigt finns det spridning och outliers i alla grupper.
Exempel på gruppskillnader
# A tibble: 2 × 4
smoker mean_charges median_charges n
<fct> <dbl> <dbl> <int>
1 no 8586. 8232. 896
2 yes 16537. 16392. 204# A tibble: 2 × 4
chronic_condition mean_charges median_charges n
<fct> <dbl> <dbl> <int>
1 no 8929. 8096. 832
2 yes 13573. 12700. 268Tabellerna visar att rökare hade betydligt högre genomsnittlig kostnad än icke-rökare. Personer med kronisk sjukdom hade också högre kostnader än personer utan kronisk sjukdom.
Regressionsmodeller
Jag jämförde två linjära regressionsmodeller. Den första modellen var enklare och innehöll variablerna age, bmi och smoker. Den andra modellen var mer omfattande och innehöll fler variabler från datasetet.
# A tibble: 2 × 3
model r_squared adjusted_r_squared
<chr> <dbl> <dbl>
1 Model 1 0.544 0.542
2 Model 2 0.748 0.744Modell 1 hade en förklaringsgrad på cirka 0.544, medan modell 2 hade en förklaringsgrad på cirka 0.748. Det betyder att modell 2 förklarade en större del av variationen i försäkringskostnaderna och därför fungerade bättre än modell 1.
Resultaten visar att rökning hade den starkaste effekten i modellen. Även kronisk sjukdom, tidigare historik, låg motionsnivå, högre ålder och högre BMI hade tydliga samband med högre kostnad. Variabler som kön, region och antal barn verkade däremot inte ha någon tydlig effekt när övriga variabler hölls konstanta.
Jämförelse mellan modellerna
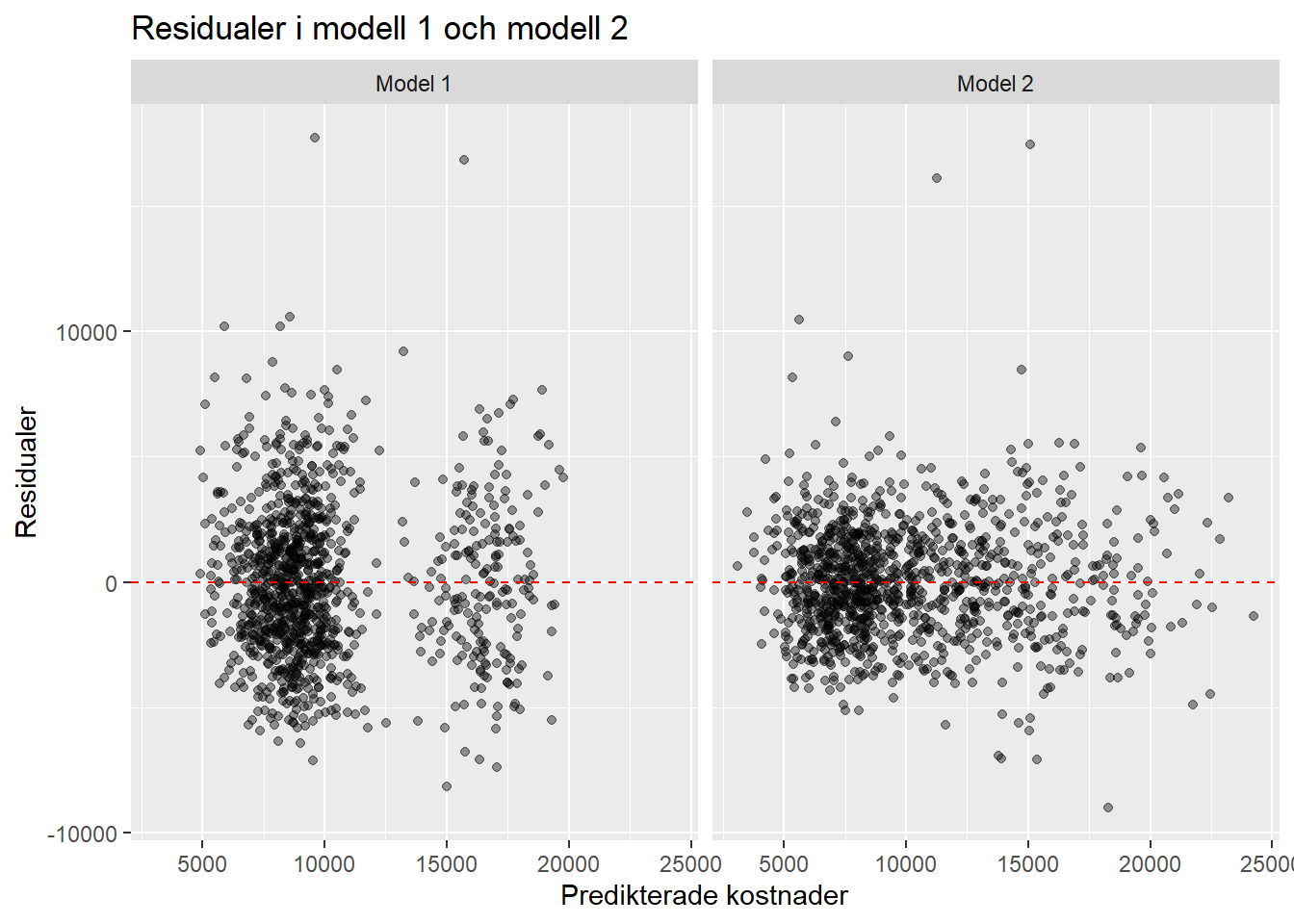
Residualplotten visar att modell 2 verkar passa datat bättre än modell 1. Residualerna är mer samlade kring noll i modell 2, vilket tyder på en bättre anpassning. Samtidigt finns det fortfarande spridning och vissa outliers, vilket visar att modellerna inte fångar all variation i datat.
Slutsatser
Analysen visar att flera faktorer verkar ha samband med försäkringskostnad. De tydligaste faktorerna i detta dataset var rökning, kronisk sjukdom, tidigare historik, motionsnivå, ålder och BMI. Även försäkringsplan verkar ha betydelse.
Den mer omfattande regressionsmodellen gav en tydligt bättre förklaringsgrad än den enklare modellen. Det tyder på att flera av de extra variablerna bidrar till att bättre förklara variationen i försäkringskostnader.
Begränsningar och möjliga förbättringar
Analysen har några begränsningar. Modellen antar linjära samband, vilket kan vara en förenkling av verkligheten. Det kan också finnas andra viktiga faktorer som påverkar försäkringskostnader men som inte finns med i datasetet. Dessutom behövde vissa saknade värden ersättas, vilket alltid innebär en viss förenkling.
En möjlig förbättring hade varit att undersöka interaktioner mellan variabler, till exempel mellan BMI och rökning. Det hade också varit möjligt att testa om vissa icke-signifikanta variabler kunde tas bort för att göra modellen enklare utan att förlora alltför mycket förklaringsgrad.
Självreflektion
Jag tycker att jag lyckades bra med att strukturera arbetet i flera tydliga steg och att genomföra datastädning, beskrivande analys, figurer och regression på ett systematiskt sätt. Jag tycker också att resultaten blev rimliga och att jämförelsen mellan två modeller gjorde analysen tydligare.
Det svåraste var att avgöra vilka variabler som skulle ingå i modellerna och att tolka resultaten på ett korrekt sätt.
Jag tycker att inlämningen motsvarar VG, eftersom jag inte bara genomfört en grundläggande analys utan också jämfört två regressionsmodeller, tolkat resultaten och diskuterat modellens styrkor, svagheter och möjliga förbättringar.